眾所周知,網站提供優質且對訪客有幫助的內容,是 Google 官方持續強調的搜尋排名關鍵因素。然而,隨著專門撰寫文章的行銷公司日益增多,優質內容的重要性似乎有時被過度強調,反而讓許多人忽略了技術性 SEO 優化同樣不容忽視。
由於技術性 SEO 的重要性難以用簡單的話來說明,所以我也一直在思考如何喚起大家的關注,直到兩周前,我接手了一個 SEO 服務個案,這個網站的排名與曝光問題幾乎都與技術性 SEO 有關,雖然兩周後網站仍在優化當中,但已經可以看到曝光量的明顯躍升,因此,我整理了這期間的優化過程,希望能透過這次分享,提醒大家在專注發展優質內容的同時,也務必隨時關注網站技術性 SEO 的健康狀態。
內容目錄
用 Google Search Console 來了解網站的 SEO 健康狀態
接手個案的 SEO 優化工作後,我的第一步就是將網站資源新增至 Search Console 中,Search Console 就是做 Google 搜尋 SEO 健檢的最佳工具,沒有之一,如果您想自己進行網站的 SEO 優化,那你的第一步應該就是把 Search Console 的功能摸透。
新增資源後,大約要等24小時之後,才能在 [成效] 單元出現數據(總點擊次數、曝光總數),所以要進行 SEO 優化,將網站資源新增至 Search Console 中,絕對是第一個步驟。
檢查 robots.txt 的檢索狀態及內容設定
在 [設定] > [檢索] 的單元之下,有一項 robots.txt 的項目,我一進來就發現 robots.txt 未正確設置,robots.txt 是一個放在網站根目錄下的文字檔案,它的主要功能是引導搜尋引擎的網路爬蟲(也稱為機器人或蜘蛛)如何在你的網站上爬行與索引內容。
Google 無法正確讀取 robots.txt,會預設為可以爬取並索引你網站上的所有內容。這聽起來可能沒什麼,但實際上可能導致問題:
- 不希望被索引的內容被收錄: 你可能有些頁面(例如測試頁、後台頁面、重複內容或不完整的頁面)原本是想透過 robots.txt 阻止爬取的,但現在它們可能會被 Google 抓取並顯示在搜尋結果中,這可能會影響用戶體驗,甚至洩漏不該公開的資訊。
- 爬蟲效率降低: Googlebot 可能會花費寶貴的「抓取預算 (Crawl Budget)」去爬取那些你原本就不想讓它看的頁面。這會導致你真正重要、想被索引的內容,被爬取和更新的頻率降低,進而影響這些頁面在搜尋結果中的表現。
- 伺服器負擔增加: 如果網站規模較大,或伺服器資源有限,Googlebot 無差別地爬取所有頁面,可能會增加伺服器的負擔,導致網站變慢或不穩定。
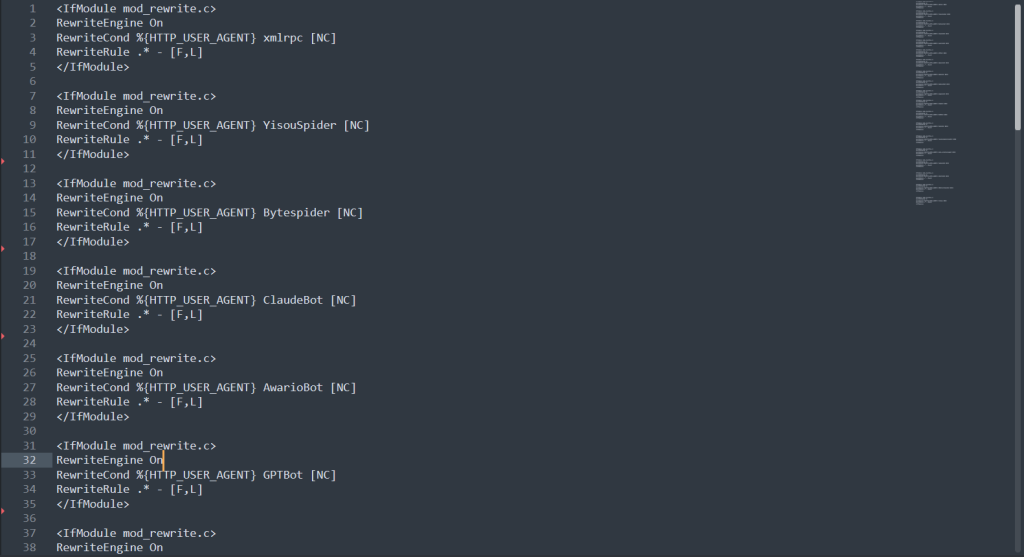
經過一番檢查之後,發現個案網站根目錄下的 .htaccess 檔案,有設置了好幾段的網址重寫(URL Rewriting)規則,把大部分的爬蟲都禁止了。
這應該是前一位工程師,認為有些爬蟲不講武德,即是設置了 robots.txt 禁止爬取,它們還是無視設定的強制爬取,於是改由網址重寫(URL Rewriting)規則來阻擋,不過把 Google 的爬蟲也一併擋掉了,就有點匪夷所思,後來才知道有其他的故事,這後面一點再說。
於是我把 .htaccess 中的上圖這些規則都移除,重新上傳 robots.txt 來規範爬蟲,先只開放 Google 及 Bing 的爬蟲,其餘先擋掉,過一陣子再觀察及做必要的調整。
網站被拖垮?元兇竟是搜尋引擎爬蟲過度檢索!
分析網站的 Log 檔案,發現有許多 404 的錯誤紀錄,但那些被要求的網址卻又是合法的正常頁面,反查這些訪客的 IP,確定大部分都是 Google 的伺服器,詢問業主為何要阻止 Google 爬蟲,才了解是原本網站反應時常變得很慢,懷疑是 Google 爬蟲惹事,所以才禁止 Google 爬蟲。
雖然在 .htaccess 中用網址重寫(URL Rewriting)規則可以阻擋爬蟲讀取網頁,但這其實是相當不恰當的作法,因為在 .htaccess 中設定重寫規則,導致特定網址返回 404 (Not Found) 或 403 (Forbidden) 狀態碼時,Googlebot 並不會立即停止來爬取該頁面,它會有一個再次檢查 (re-crawl) 的過程,以確認這個頁面是否真的消失了或無法訪問,於是過沒幾天又再來爬,持續造成網站主機的負擔。
理解了來龍去脈之後,還原這事件的始末,竟然是工程師為了解決爬蟲造成網站主機 Loading 過重,影響網站正常運作,於是用 404 的方式去阻止爬蟲,結果造成爬蟲更積極來嘗試爬取網頁,一時間造成主機負載更重,網站變得更慢。
在 robots.txt 中設定禁止爬取的規則
為什麼這個個案的網站一開始讓 Google 爬取,會造成主機負擔呢?這是因為如果沒有在 robots.txt 檔案中設定適當的限制,搜尋引擎爬蟲可能會抓取網站上所有可連結的網址。然而,這些網址中,許多內容可能大同小異,甚至存在大量重複,其實沒有必要讓爬蟲耗費資源逐一檢索。
因此,robots.txt 檔案的功能不僅止於設定哪些搜尋引擎爬蟲被允許或禁止進入你的網站,即使你允許 Google 爬蟲,也可以進一步利用 robots.txt 來限定某些符合特定條件的網址路徑,禁止它們被爬取,從而更有效地管理爬蟲行為。
不同網址卻內容重複的情形有哪些呢? 我在這裡舉一個常見又容易理解的範例。
假設你的某個頁面(例如某一商品分類下),有N件商品,它們會以預設的排序方式出現,網站通常會提供多種的排序條件,例如依據熱銷度、買家評分、上架時間、售價等等,很多網站也同時會提供正排及反排,售價由低到高、或由高到低,這麼多的排序組合,它們的網址都會不一樣,但它們呈現的內容其實都是那N件商品,若再加上可設定每頁顯示幾筆商品,就可以再產生超多種的組合,但其實都是哪N件商品,幾乎都是重複的內容。
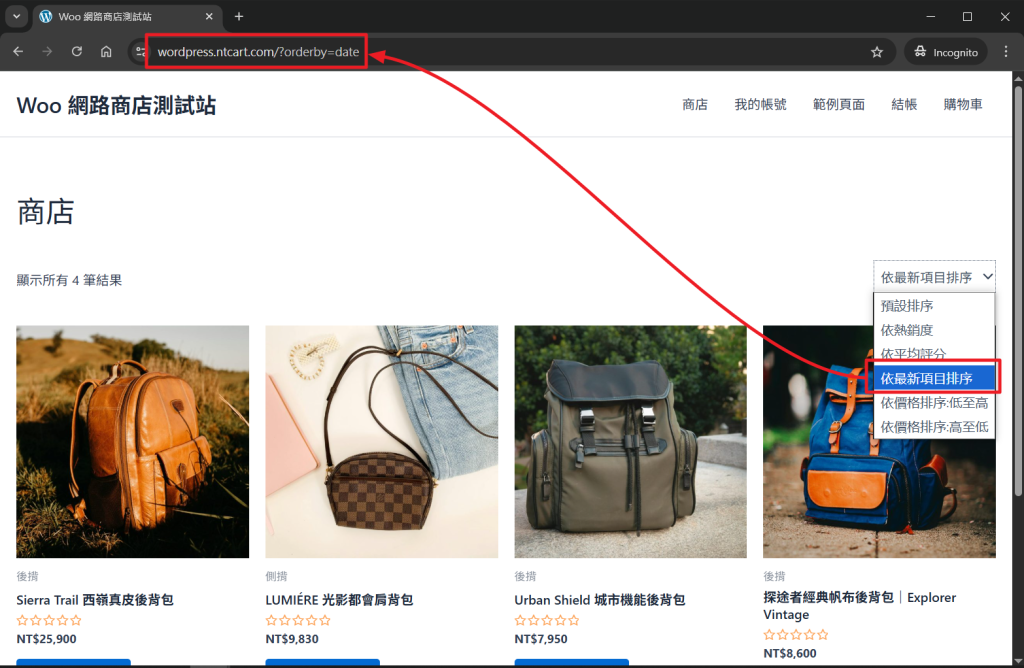
了解問題之後,我在 robots.txt 中設定禁止爬取的規則如下圖,只開放 Google 及 Bing 的爬蟲,但限制不要爬取帶有特殊參數的網址,因為它們在該網站中,都是屬於重複性內容的網址,如此一來,就可以達到開放 Google 及 Bing 的爬蟲來爬取網頁內容,又不至於爬取過度造成網站嚴重負擔。
各位不要照抄這邊的設定,因為不同的網站有不同的參數,這需要量身訂製,需要服務的人,請洽詢 24cc.com@gmail.com。
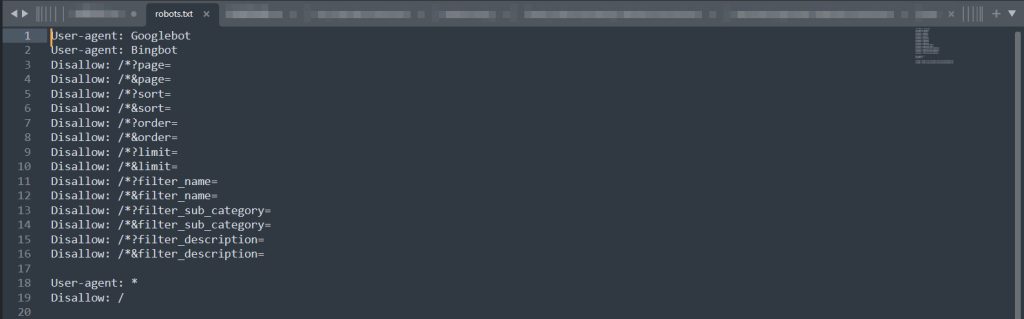
robots.txt 檔案問題修正之後,Google 已偵測 robots.txt 為有效,開啟 [檢所統計資料] 的報表,就可以了解 GoogleBot 進行檢索的統計數據了。
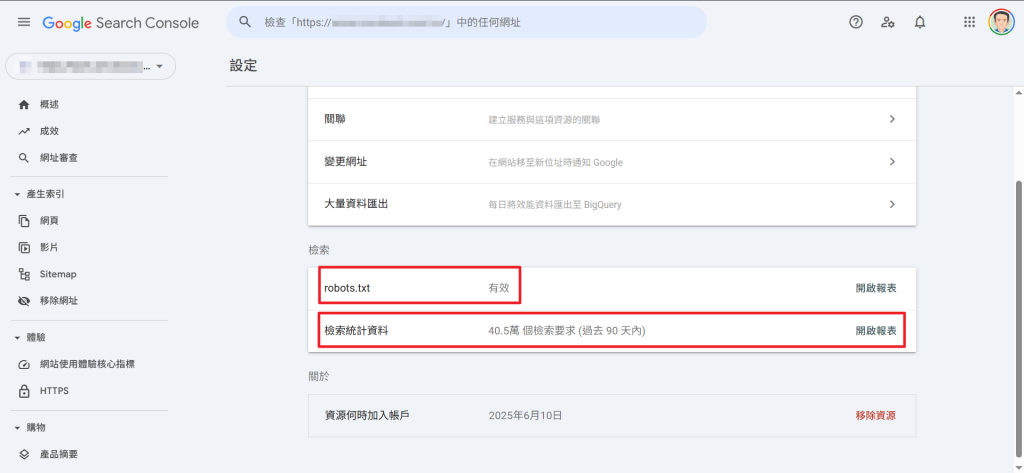
在檢索統計報表中(下圖)可以看到,robots.txt 檔案問題修正之後,Google 的爬蟲已不再爬帶有特定參數的網址,於是檢索次數在 2025/06/20 之後,就明顯降了下來,網站也不再因為爬蟲的過度爬取而被癱瘓。
如果您的網站也時常很遲鈍,請也檢查一下 Google 的檢索次數及 robots.txt 的設定吧。
Sitemap 的提交更新與限制
即使沒有提交 sitemap,Google 也能透過其他管道發現你的網頁,進而檢索收錄,不過透過 sitemap 仍是比較迅速讓 Google 知道新網頁的方式,不論是增加新文章或是新商品,所以確保 sitemap 提交及讀取正常,都是我們健檢 SEO 必定會檢查的項目。
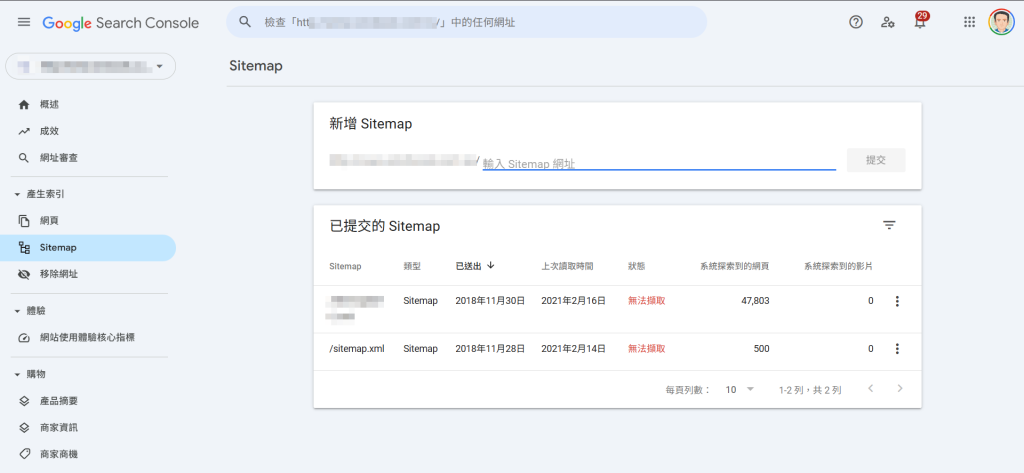
個案的 Sitemap 狀態如上圖,曾提交過 Sitemap,也曾被讀取成功,判斷應該是網站改版造成原本的 Sitemap 功能失效,這不太難,如果你也遇到相同問題,刪除舊的 Sitemap,重新提交新的即可,現在的購物網站系統、或是部落格系統,應該都有提供 Sitemap 的功能,向廠商詢問一下 Sitemap 的網址,或問一下 ChatGPT。
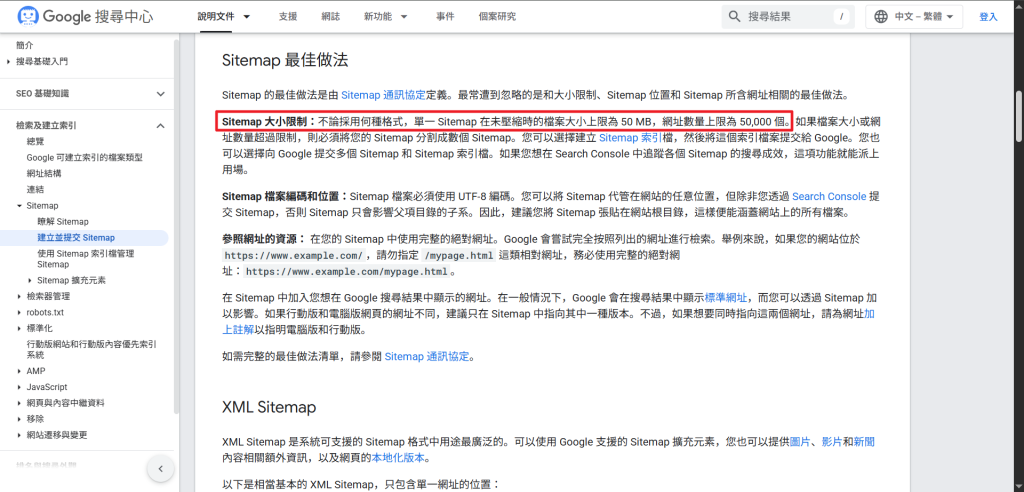
不過個案的 Sitemap 問題還沒結束,由於這個網站的商品數極多,所以粗判提交的網址數可能有接近十萬個,而 Google 對於 Sitemap 的大小限制是:不論採用何種格式,單一 Sitemap 在未壓縮時的檔案大小上限為 50 MB,網址數量上限為 50,000 個,其他有關 Sitemap 的說明,建議請參考 Google 的官方文件: 建立並提交 Sitemap。
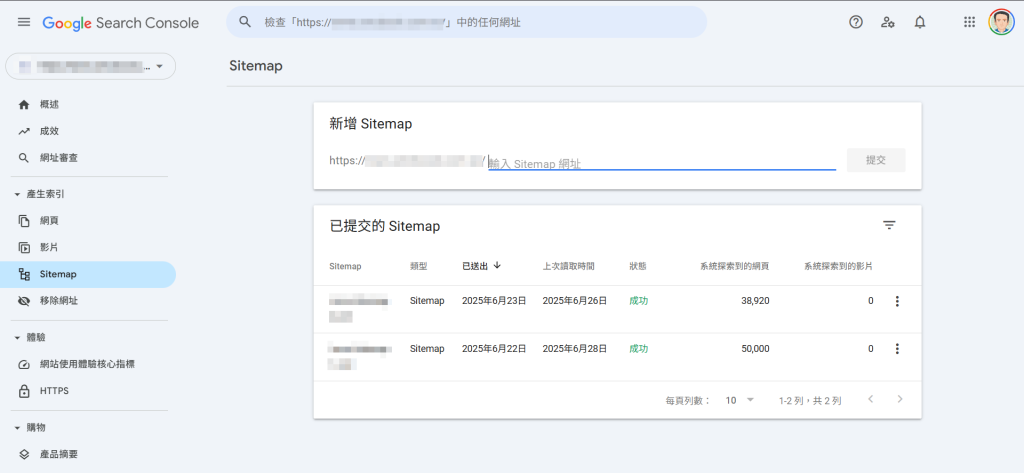
前面提到大部分的網站系統或平台,都有提供 Sitemap 的功能,然而並不是每一個網站都有特別處理網址數超過 50,000 個的問題,個案這個網站的系統也是,於是我們為它客製了將 Sitemap 自動拆分的功能,讓 8 萬多個網址都能讓 Google 讀取得到。
為重複或相似的網頁指定標準網址
「標準網址」是指 Google 從一組重複網頁中選出的最具代表性網頁的網址。這個程序經常稱為「簡化」作業,可讓 Google 在搜尋結果中針對重複內容只顯示一種版本。
網站含有重複內容的原因很多,包括:
- 地區變化版本:例如美國和台灣的某個部分內容,可透過不同網址存取,但基本上是相同語言的相同內容。
- 裝置變化版本:例如同時提供行動版和電腦版網頁。
- 通訊協定變化版本:例如 HTTP 和 HTTPS 版本的網站。
- 網站函式:例如套用類別網頁中排序與篩選功能的結果,前面提到的範例就是這種。
- 意外變化版本:例如,檢索器不小心存取了網站的示範版本。
網站上的部分重複內容屬於正常內容,沒有違反 Google 的垃圾內容政策。不過,如果有許多不同網址導向相同內容,可能造成使用者體驗不佳 (例如,使用者可能會想知道哪個網頁是正確的網頁,以及兩者之間是否有差異),讓您更難追蹤「內容」在搜尋結果中的成效。不只如此,前面提到因為爬蟲爬取重複內容,造成爬去過度,影響網站主機正常運作,也是應該避免的事。
現在的購物網站系統或是部落格系統,應該都已經內建指定標準網址的功能了,照理說不需要特別去擔心,不過個案發生一種狀況,就是常常發現在 Google 搜尋結果出現的,有時並不是標準網址的那一頁,讓我們一度懷疑是不是網站系統標準網址的功能出現異常。
後來確認標準網址的功能是正常的,這部分可以透過網址原始碼,檢查 rel=”canonical” 的設定來確認,至於為何搜尋結果優先出現非標準網址,推斷應該是標準網址持續因網站不給爬取,讓 Google 以為標準網址的那一頁已不存在,所以改用非標準網址作為查詢結果,可見技術性 SEO 的各種設置環環相扣,唯有全面性的整頓梳理,才能發揮最大的效益。
網頁的結構化資料標記
結構化資料是一種讓搜尋引擎(像是 Google)能更聰明地「讀懂」你網頁內容的特殊標籤。
例如購物網站的商品頁面,對我們人來說,一眼就能看到標題、價格、品牌、顏色、庫存這些資訊。但對搜尋引擎的機器人來說,它看到的是一大堆程式碼和文字,要理解這些文字到底代表什麼意義,其實沒那麼容易。
結構化資料能把網頁上的重要資訊,用一種機器人能直接理解的標準格式,明確地標註出來。這樣一來,搜尋引擎就不需要自己去猜測這些資訊是什麼,它能精準地辨識出網頁上的各種資料,並進行分類。
有無結構化資料的差異:
如果你的購物網站上架了一個新的背包:
- 沒有結構化資料的網頁: Google 爬蟲讀取你的網頁,它看到文字「原價 $2500,特價 $1999」、「品牌:Outdoor Gear」、「顏色:藍色、黑色」、「目前有貨」等等。雖然它會知道這些文字存在,但它可能無法立即、精確地判斷「$1999」是「特價」,「Outdoor Gear」是「品牌名稱」,「藍色、黑色」是「可選的顏色」,或這些價格對應的是哪款商品。
- 有結構化資料的網頁: 你透過結構化資料,直接明確地告訴 Google:
- 這是一個產品 (Product)。
- 產品名稱是「登山輕量背包」。
- 品牌 (brand) 是「Outdoor Gear」。
- 平均評價 (aggregateRating) 是 4.5 顆星,有 120 人給過評價。
- 價格 (price) 是 1999 元,幣別 (priceCurrency) 是台幣 (TWD)。
- 庫存狀態 (itemAvailability) 是「有貨」。
- 這張圖是產品主要圖片 (image)。
結構化資料有什麼好處?
當 Google 能精確讀懂這些資料後,你的網頁在搜尋結果頁面(SERP)上就會有更多機會以**「豐富搜尋結果」(Rich Results 或 Rich Snippets)**的形式呈現。
例如,當有人搜尋「登山背包」時,你的網站連結可能不只顯示標題和簡介,還會直接在搜尋結果中顯示:
- 商品的價格
- 星級評價
- 是否有庫存
- 甚至是產品圖片
這些額外顯示的資訊,會讓你的網站在眾多搜尋結果中更吸睛、更有辨識度,大大增加用戶點擊進你網站的機會,進而提升網站流量。它不僅能讓搜尋引擎更理解你的內容,也能讓你的網頁在搜尋結果中脫穎而出!
要檢查您的網頁是否有支援結構化資料,可以使用 Google 官方提供的複合式搜尋結果測試工具。
個案網站因為建置於 2018 年之前,可能那個年代對於結構化資料還不是那麼重視,所以沒有內建支援,於是我們協助客製了這個功能,至少讓商品頁面都提供了結構化資料區塊,讓 Google 能更正確解析網頁的資訊內容,這對於搜尋結果的排名當然也是加分的。
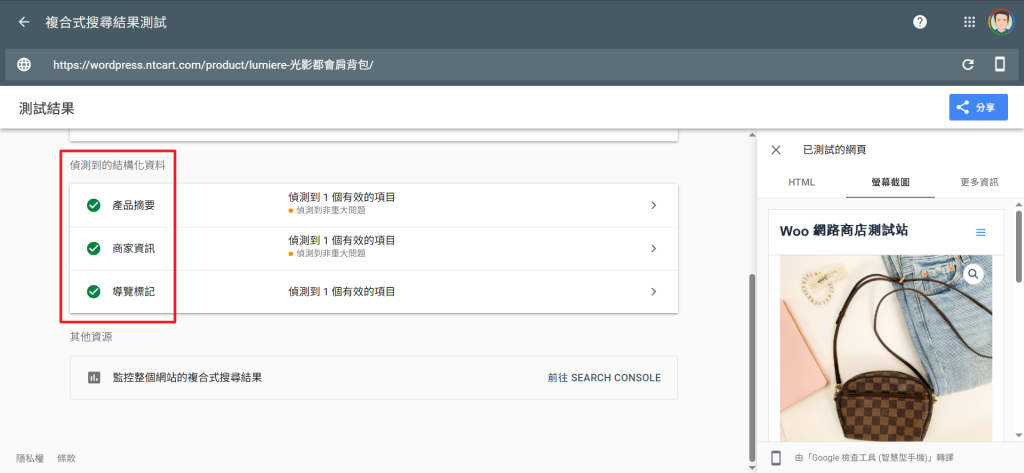
上圖是我們的一個測試網站的商品頁,如果你的網頁有支援結構化資料,測試結果應該類似這個樣子,至於有偵測到非重大問題,通常是網頁沒有提供客戶評論的資料之類的,有當然很好,沒有的話其實也沒太大關係。
網頁內含 HTTP:// 連結的混合內容錯誤
當您的網頁中,含有 HTTP:// 的連結時,瀏覽器會偵測到並提出警示,這是混合內容錯誤。
網頁發生這種狀況,除了給訪客留下不安全的印象之外,對於 Google 搜尋來說,也是一個排名扣分的因素,總之,遇到這種狀況,最好還是將它排除為妙,前面提到的個案,也出現了這個狀況,所以跟大家分享一下我們如何排除它。
許多營運多年的網站,其內容中常見到含有 HTTP:// 開頭的連結,這是因為在過去,大部分網站都採用 HTTP 協定,所以當時編輯者在建立外部連結時,很自然地就直接使用了對方的 HTTP 網址。
即使後來對方的網站已經升級支援了更安全的 HTTPS:// 協定,這些舊有的網頁內容中的連結並不會自動更新,因此,這些「不安全」的 HTTP 連結就這樣被遺留下來,存在於網站內容中。
另外一種常見的情形是,網站本身過去也經歷過 HTTP:// 的時期,故在 HTTP:// 期間建立的內部連結,也有可能被存成 HTTP:// 的形式,即使後來網站已支援 HTTPS://,這些 HTTP:// 的連結也很有可能因此而被遺留下來。
修正這些問題的方式,是直接到資料庫中,找到可能儲存含有 HTTP:// 連結的 table 及欄位,然後用 SQL 的 REPLACE 語法直接將它們更新為 HTTPS:// 即可。
最後再做一個 URL Rewrite 的設定,將訪問 HTTP:// 的請求,導向 HTTPS:// 的對應網址,讓即使訪客誤點了 HTTP:// 的網址,也會被導向 HTTPS:// 的網址。
以上的工程大約可以修正 90 幾 % 的 HTTP:// 問題,剩下的零星狀況,需要 Case By Case 去處理,這邊就不再多介紹。
技術性 SEO 問題修正後的成效
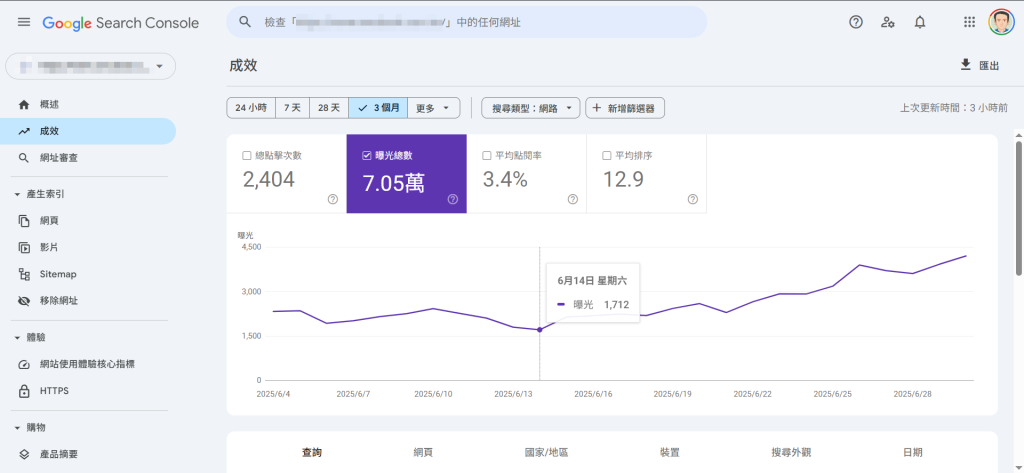
這個個案執行技術性 SEO 優化至今將近 2 周,主要的優化作業雖已大致完成,在這期間,我們並未幫網站增加任何一篇文章或網頁,純粹只有技術性 SEO 的優化,雖然 SEO 改善的成效不會立即呈現出來,不過對比6月上半,6月下半的曝光量已有明顯的成長,等過一段時間讓這些技術性 SEO 優化陸續發酵後,再與各位分享成效。
如果您覺得您的網站內容豐富且都是自行編寫,但是 SEO 的成效不滿意,歡迎與我們聯絡,我們提供技術性 SEO 的健檢服務,檢查無須費用,檢查後會依健檢結果提供報價(每個案子都會不同),改善後曝光數成長到承諾的%數才須付全額費用,成長未達 5% 則完全不收費,請 Email: 24cc.com@gmail.com 洽詢。
開源電商創辦人,投入購物網站建置工程技術,至今已累計有 20 年的經驗,建置服務超過 1000 個網站,為台灣最專業的 OpenCart 技術專家。
經營行銷科技洞察FB社團,長期分享行銷、SEO、GA4、社群、廣告等文章,是電商及網路行銷雙棲顧問。